Upgrading to ESXi 5.0 Update 1 using VMware Update Manager
 Sam McGeown
Sam McGeown I’m currently updating a very small 4-host cluster built for a specific application within our datacentre, the hosts are IBM HS22 blades. Since we have the VMware Update Manager infrastructure in place already, I downloaded the IBM ESXi 5.0 Update 2 ISO and imported it into Update Manager, created a baseline and then applied it to the cluster. I scanned the cluster with the baseline and was issued this warning for each host:
I’m currently updating a very small 4-host cluster built for a specific application within our datacentre, the hosts are IBM HS22 blades. Since we have the VMware Update Manager infrastructure in place already, I downloaded the IBM ESXi 5.0 Update 2 ISO and imported it into Update Manager, created a baseline and then applied it to the cluster. I scanned the cluster with the baseline and was issued this warning for each host:

That’s fine - there is an option to remove those modules when you remediate the host.
Part 1 - Upgrading doesn’t go entirely to plan
I went ahead and remediated my first host, which was duly placed in maintenance mode and then bombed out at 7% complete with the error:
Software or system configuration of hostis incompatible. Check scan results for details.

Searching for this error led me to this Communities post which in turn pointed to a VMware KB which recommends disabling the Ethernet over USB interface on the blade configuration: http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2006133
The Ethernet over USB interface is only used if you have the IBM management agents installed - this cluster did not.
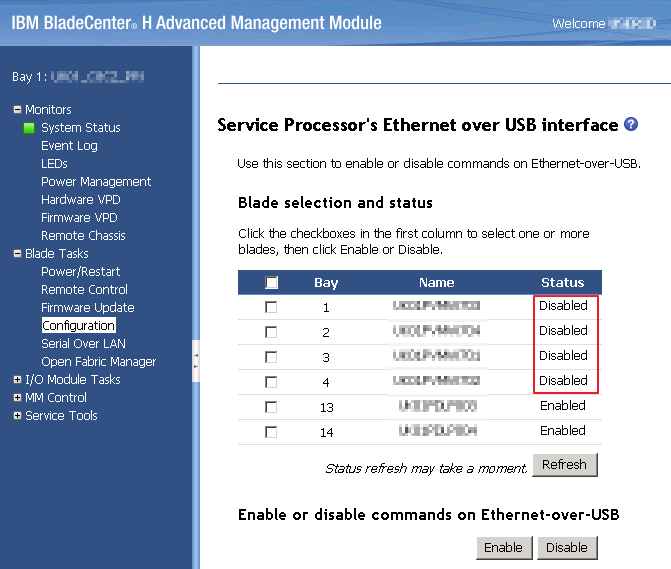
Once I’d change this the Upgrade worked on 1 out of 4 blades - the remaining 3 threw this error (at the annoyingly late stage of 92%!):
Cannot execute upgrade script on host.

A further search took me to Upgrading from ESXi 4.0 Update 1 or Update 2 to ESXi 5.0 using vCenter Update Manager fails with the error: Cannot run upgrade script on host. I didn’t have the errors in the vua.log, but following the procedure did resolve the issue on a further 2 of the hosts.
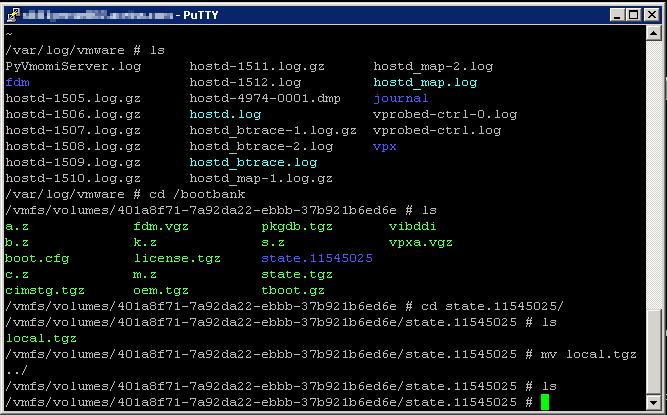
The resolution is to SSH to the host in question and browse to the /bootbank folder. List the contents and you see a state.xxxxxxx folder - move inside the folder and you see a local.tgz file. The KB tells you to move that file to the parent folder and try again.
The final hurdle to upgrading was to remove the space in the name of the management network on the remaining host. Upgrading from ESXi 4.x to ESXi 5.0 using Update Manager fails with the error: integrity.fault.HostUpgradeRunScriptFailure points to the port group name for the Management Network needing to be less than 20 characters - which the default (“Management Network”) is. Since our management network is left to default, I moved on - but later read a forum post mentioning the need to remove spaces.
Finally the install process was working - however there were other issues once I’d upgraded!
Part 2 - MSCS RDM LUNs and ESXi 5 cause an incredibly long boot time
The hosts took an _exceedingly _long time (read 1-2 hours) to progress past “vmw_satp_alua loaded successfully” - Alt-F12 showed that the boot was going forward but I’m talking 3 hours in total to boot! Subsequent reboots did not improve the situation, and this wasn’t an issue with the ESXi 4 installation. We have RDMs attached to these hosts for MSCS, and this led me to this article: ESX/ESXi hosts hosting passive MSCS nodes with RDM LUNs may take a long time to boot. (If you use iSCSI this VMware KB is more relevant).
All four of hosts have the RDM luns presented and although only two of the hosts actually run the Microsoft Cluster Services, the slow boot affected all four. The problem is that when the host boots it tries to claim all LUNs that it can see - including the RDMs which are reserved for the Cluster. As the doc puts it better than me:
ESXi 5.0 uses a different technique to determine if Raw Device Mapped (RDM) LUNs are used for MSCS cluster devices, by introducing a configuration flag to mark each device as “perennially reserved” that is participating in an MSCS cluster. During a boot of an ESXi system the storage mid-layer attempts to discover all devices presented to an ESXi system during device claiming phase. However, MSCS LUNs that have a permanent SCSI reservation cause the boot process to elongate as the ESX cannot interrogate the LUN due to the persistent SCSI reservation placed on a device by an active MSCS Node hosted on another ESXi host.
Following the procedure in the VMware KB, I found the naa.xxx ID for each the 14 RDM LUNs (and had to manually type them out, grrr) and then enabled SSH on the newly upgraded hosts to send the following command:
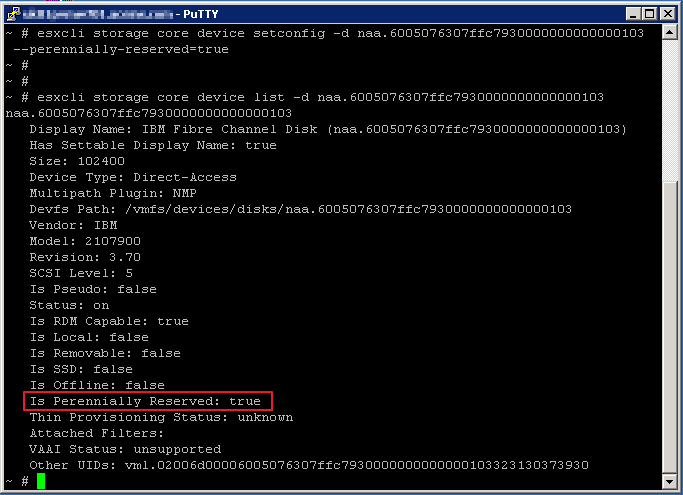
esxcli storage core device setconfig -d naa.6005076307ffc7930000000000000103 --perennially-reserved=true
and verified it with the command
esxcli storage core device list -d naa.6005076307ffc7930000000000000103
Rebooting then took about 10 minutes, most of which was the UEFI. Unfortunately this process needed to be run on each host, and each host had to boot with the RDM LUNs connected to then be able to change their reservation. Unfortunately, with each host taking several hours to boot through the 14 RDMs, stepping through to upgrde the cluster hosts took an awful long time! I’m not looking forward to doing the “big” clusters with 20, 30 and 50 hosts.
Sam