Now 6 has been GA a while and I have a little bit of time, I have begun the lab upgrade process. You can see a bit more about my lab hardware over on my lab page.
Upgrading to VSAN 6.0#
The upgrade process for VSAN 5.5 to 6.0 is fairly straight forward
- Upgrade vCenter Server
- Upgrade ESXi hosts
- Upgrade the on-disk format to the new VSAN FS
Other parts of this guide have covered the vCenter and ESXi upgrade, so this one will focus on the disk format upgrade. Once you’ve upgraded these you’ll get a warning on your VSAN cluster:

Because I’m only running a 3 host VSAN there are some special considerations:
If I evacuate the data from each host as I upgrade the disk format (which is an absolute must in a production environment) it will fail. This is because my failures to tolerate is set at 1, which means VSAN needs 3 copies of the data to rebuild (two mirrors and a witness). If I evacuate one of my three hosts, then there are not sufficient hosts remaining to maintain that protection level. For this reason, I must use the “Ensure accessibility” maintenance mode - which means if I lose hardware while doing the upgrade, I will lose data.
When I put each host in maintenance mode, I need to make sure that I have enough capacity in the other VSAN nodes to accommodate the data being moved around.
I also need to use an option to allow reduced redundancy while doing the upgrade, which again exposes me to data loss IF I lose hardware while doing the upgrade.
Having said all of that, I have a good backup of my lab and actually, I don’t care that much if I lose them 🙂
Checking VSAN status#
Anyone familiar with managing VSAN at more than a cursory level will have seen and heard of the RVC tool, if you haven’t I would strongly suggest the excellent Manage VSAN with RVC series over at virten.net to learn the basics. Another good read before doing the upgrade is Rawlinson Rivera’s upgrading VMware Virtual SAN 6 post, and the vSphere 6 Upgrading the Virtual SAN cluster documentation.
SSH onto the vCSA and log onto the RVC tool
rvc [email protected]@vcsa-01

If you’re familiar with PowerShell, rvc reminds me a little of using a PSDrive to navigate the structure of vCenter, but it’s not exactly intuitive.
Note the space must be escaped with a “" and the “computers” folder in there too.
vsan.cluster_info /vcsa-01/DefinIT\ Lab/computers/HPN54L/
There’s a lot of output from that command, but you should see various clues such as “VSAN enabled: yes” and see the role of each host in the cluster “Cluster role: master”.
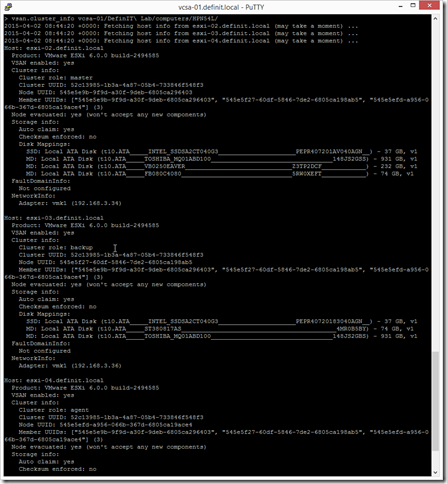
You can also see the “Auto claim: on” setting - this means VSAN will automatically claim new disks (automatic mode). This is fine for the normal operation of VSAN but needs to be changed to manual for the upgrade process. Use the vsan.cluster_change_autoclaim command to disable auto-claim. Use the option -disable, or -d to disable.
vsan.cluster_change_autoclaim -d /vcsa-01/DefinIT\ Lab/computers/HPN54L/
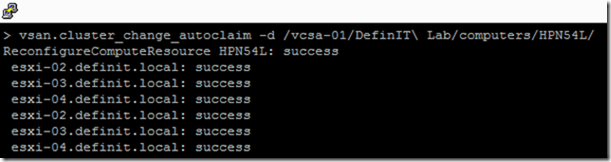
You can also see from the “Node evacuated” message, that I’m still in maintenance mode. Somewhat counter-intuitively, the cluster needs to be out of maintenance mode in order to upgrade! This is because it needs to evacuate data on the disks, and it can’t if the other nodes won’t accept it.
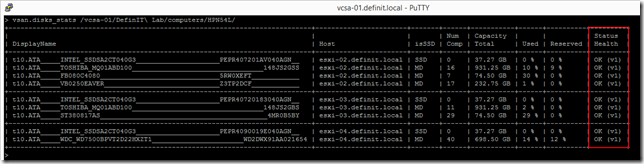
Next up use vsan.disk_stats to verify the health status of all devices in the cluster:
vsan.disks_stats /vcsa-01/DefinIT\ Lab/computers/HPN54L/
Verify that all components are OK in the Status Health column.
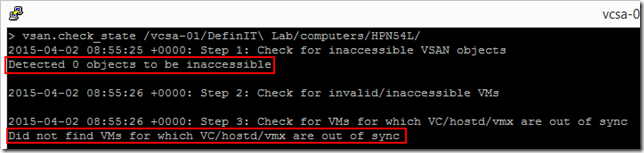
Next up use the vsan.check_state command to ensure that everything is in-sync:
vsan.check_state /vcsa-01/DefinIT\ Lab/computers/HPN54L/
You can see that 0 objects are inaccessible and everything is in sync:
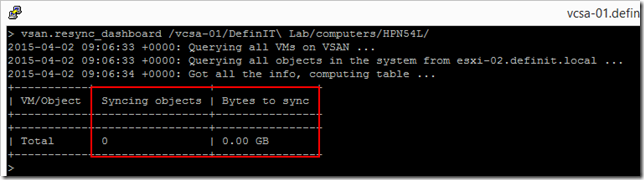
Another method to do this is to use the vsan.resync_dashboard command:
vsan.resync_dashboard /vcsa-01/DefinIT\ Lab/computers/HPN54L/
Finally, I need to do a “what if” scenario to check what would happen if I lost a host:
vsan.whatif_host_failures /vcsa-01/DefinIT\ Lab/computers/HPN54L/
My lightly used VSAN would not have a capacity problem if I lost a host:
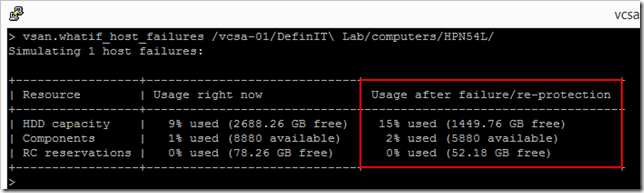
So, from the results above I can conclude that my VSAN cluster is healthy, and I can move on to the disk upgrade.
Performing the disk format upgrade#
Upgrading the disk format is a single command for the whole cluster, using the option I mentioned before to proceed even with reduced redundancy (required for a 3-host VSAN)
vsan.v2_ondisk_upgrade --allow-reduced-redundancy /vcsa-01/DefinIT\ Lab/computers/HPN54L/
This goes through the process of updating all the disks in the cluster and can take quite a while depending on the number and size of disks, and the number of objects stored on them. The first time I ran the upgrade, it failed because one object did not upgrade successfully, even though all the disks were correctly upgraded.
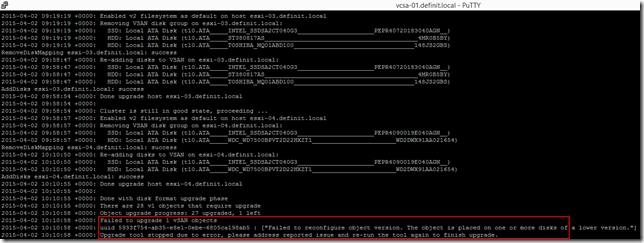
I simply re-ran the upgrade command to upgrade the last object:
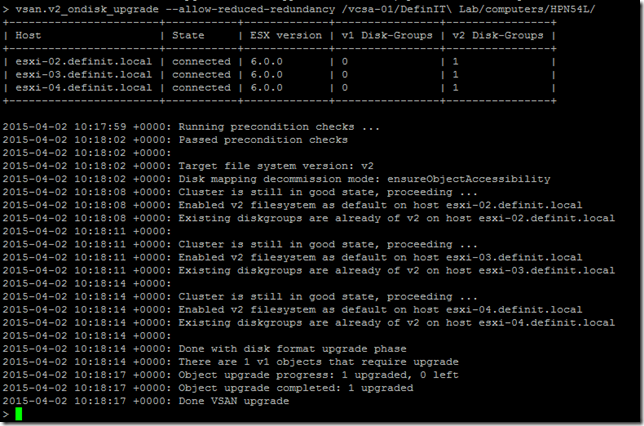
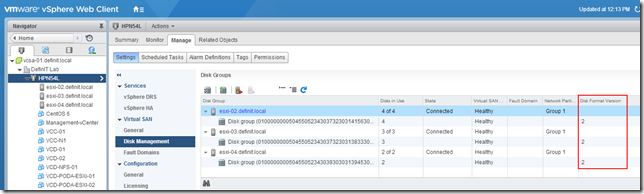
And that’s my VSAN upgraded, I can verify the version of the disks in the web client: