
 I ran into this problem at a customer site where all the Log Insight nodes were changed due to some IP address conflicts. I think the problem occurred because the IP addresses were all changed and the VMs shut down, without time for the application to update the node IPs.
I ran into this problem at a customer site where all the Log Insight nodes were changed due to some IP address conflicts. I think the problem occurred because the IP addresses were all changed and the VMs shut down, without time for the application to update the node IPs.
The symptoms:
- The web interface was down, a netstat -ano | grep -i “443” showed the service was listening
- _service loginsight status|restart|stop|start _hung and then timed out on the Master node
- The loginsight service was not running on the Worker nodes
- /var/log/loginsight/runtime.log contains warning messages about “Cassandra cluster not ready yet”

- Running /usr/lib/loginsight/application/lib/apache-cassandra-*/bin/nodetool status showed the two data nodes down (DN) and used the old IP address

All of the nodes were up with their new IP addresses, however Cassandra on the Master node was still looking for the old IP addresses for the Worker nodes. The Worker nodes were in a similar state, knowing their own new IP addresses but not being able to update the Master node because they didn’t have the Master node’s new IP address.
To fix the problem I edited the latest Log Insight configuration file on each of the nodes and updated the IP addresses for Workers under the daemon hosts sections, which were still on the old IP address. As you can see below, the Master node is defined by FQDN and not IP address, which is why the service starts on the Master, but then hangs waiting for a second node.
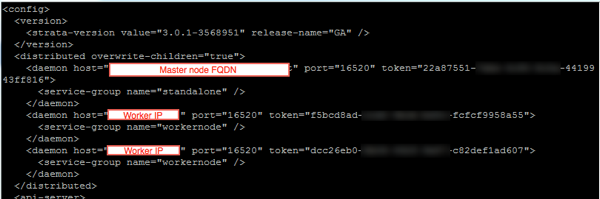
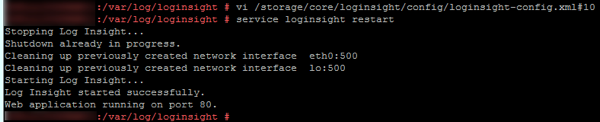
Once the Worker nodes’ configuration was updated with the correct IPs I was able to start the loginsight service (service loginsight start).
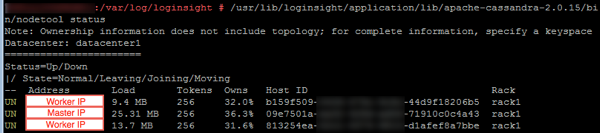
I then checked the Master node’s Cassandra status using the nodetool to ensure that the IP address for the Worker node was updated to the new IP.
At this point the Log Insight web interface was availabe, but the Admin/Cluster page showed an error - I restarted the Master node Log Insight service which resolved the issue.