Vault in Kubernetes: Rotating Static Secrets31 July 2026·1519 words·8 minsSam McGeownHashiCorp Kubernetes Vault Kubernetes VSO Secrets Management GitOps
Vault Secrets in Kubernetes: Setting up Vault Secrets Operator28 July 2026·1567 words·8 minsSam McGeownHashiCorp Kubernetes Vault Kubernetes VSO Secrets Management GitOps
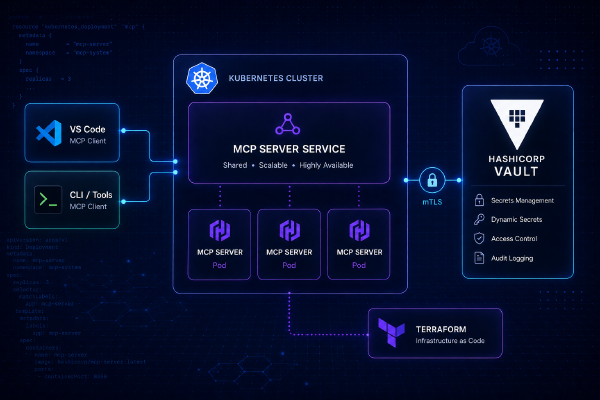
Running HashiCorp MCP Servers as a Shared Kubernetes Service15 May 2026·1678 words·8 minsSam McGeownInfrastructure AI Kubernetes Helm Mcp Vault Terraform Hashicorp
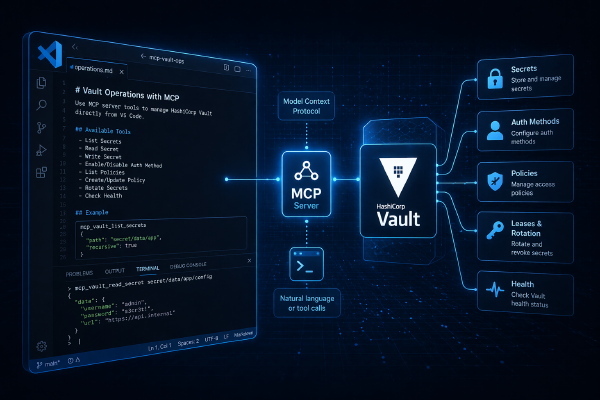
From secrets to systems: Vault MCP in AI-driven workflows24 April 2026·2252 words·11 minsSam McGeownHashiCorp AI Vault Mcp AI Security Hashicorp Pki
Building a production-grade Kubernetes lab16 April 2026·2572 words·13 minsSam McGeownKubernetes Homelab Kubernetes Flux GitOps Homelab Cilium Longhorn Vault
Setting up VSCode and Copilot for Terraform code generation6 March 2026·1479 words·7 minsSam McGeownAI Automation Mcp Skills Context Terraform VSCode
Understanding instructions, context, skills and MCP servers for code generation5 March 2026·1434 words·7 minsSam McGeownAI Mcp Skills Context
HashiCorp Certified: Terraform Associate (003) Exam Experience15 October 2025·709 words·4 minsSam McGeownCareer Community Terraform Hashicorp Certification
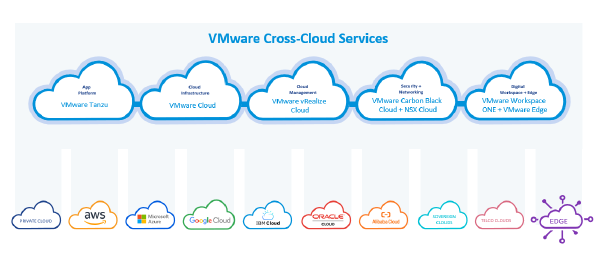
VMware Cloud Expert - Multi-Cloud Builder3 November 2022·394 words·2 minsSimon EadyVMware Multi-Cloud Multi-Cloud Builder VMware Cloud Expert Multi-Cloud Vmware Cloud Native
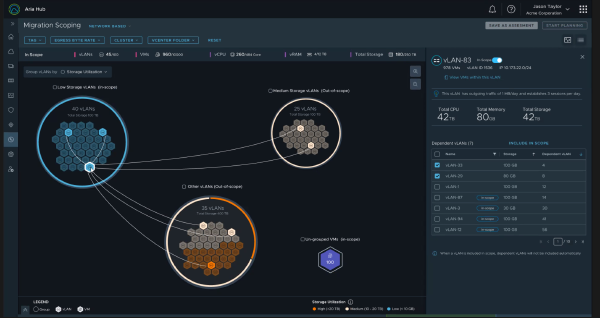
VMware Aria - Unified Multi-Cloud Management19 September 2022·489 words·3 minsSimon EadyVMware Aria VRealize Operations Aria Operations Multi-Cloud Vmware Cloud Native Applications
Looking forward to VMware Explore - the artist formerly known as VMworld4 July 2022·511 words·3 minsSam McGeownCareer VMware Vmug Vmworld VMware Explore